
Jak mawia Wieszcz, prędzej czy później nadchodzi taki czas, że trzeba albo zacząć srać, albo opuścić wychodek.
Dotychczas napisałem już osiem części poradnika o hurtowniach danych, a tak naprawdę żadnych konkretów. Dziś więc czas na pokazanie działającego, kompletnego przykładu.
Przykład będzie naprawdę prościutki. Głównie dlatego, że jestem leniwy, ale oficjalnie po to, żeby nie zanudzić Czytelników. O ile w ogóle jest ich więcej niż jeden.
Zanim zaczniemy, kilka założeń wstępnych:
- Wszystko odbywa się w jednej bazie danych
- Poszczególne warstwy hurtowni "siedzą" w osobnych schemas, nazwanych odpowiednio: stage, landing, xref, edw, dmarts (tej ostatniej schema nie będziemy jeszcze używać)
- Mamy już dane załadowane do warstwy stage
Warunek numer 3 postaram się zapewnić na samym początku - wygenerujemy sobie kilka przykładowych rekordów do warstwy stage. W rzeczywistości rekordy będą spływać do stage z zewnętrznych systemów źródłowych, za pomocą osobnego ETL-a.
OK, lecimy.
Najpierw stworzymy sobie tabele w warstwie stage i wypełnimy je przykładowymi danymi:
IF NOT EXISTS ( SELECT * FROM sys.schemas WHERE name = 'stage' )
EXEC sys.sp_executesql N'CREATE SCHEMA stage'
GO
IF NOT EXISTS ( SELECT * FROM sys.objects WHERE object_id = OBJECT_ID('stage.s_crm_klient') AND type = 'U')
CREATE TABLE stage.s_crm_klient (
klient_id INT NOT NULL
, klient_imie NVARCHAR(MAX) NULL
, klient_nazwisko NVARCHAR(MAX) NULL
, klient_nr_vat VARCHAR(20) NOT NULL
, src_system_id SMALLINT NOT NULL
)
GO
IF NOT EXISTS ( SELECT * FROM sys.objects WHERE object_id = OBJECT_ID('stage.s_fakt_client') AND type = 'U')
CREATE TABLE stage.s_fakt_client (
id INT NOT NULL
, client NVARCHAR(300) NULL
, rating CHAR(1) NULL
, vatno NCHAR(10) NULL
, src_system_id SMALLINT NULL
)
TRUNCATE TABLE stage.s_crm_klient;
TRUNCATE TABLE stage.s_fakt_client;
INSERT stage.s_crm_klient(klient_id, klient_imie, klient_nazwisko, klient_nr_vat, src_system_id)
VALUES ( 1, N'Jan', N'Kowalski', N'PL12983764', 1)
,( 2, N'Adam', N'Malinowski', N'PL16239487', 1)
,( 3, N'Grzegorz', N'Brzęczyszczykiewicz', N'PL23087893', 1)
GO
INSERT stage.s_fakt_client(id, client, rating, vatno, src_system_id)
VALUES ( 9812, N'John Smith', N'A', N'GB90418273', 2)
, ( 4536127, N'Adele O''Reilly', N'B', N'IE43998237', 2)
, ( 912398, N'Jan Kowlaski', N'C', N'PL12983764', 2)
GO
Oprócz tego potrzebujemy również tabeli z listą systemów źródłowych, wraz z ich kodami, identyfikatorami oraz priorytetami:
IF NOT EXISTS ( SELECT * FROM sys.objects WHERE object_id = OBJECT_ID('dbo.system') AND type = 'U')
CREATE TABLE dbo.system (
id BIGINT NOT NULL
, kod VARCHAR(5) NOT NULL
, nazwa VARCHAR(30) NOT NULL
, priorytet SMALLINT NOT NULL
, CONSTRAINT PK_system PRIMARY KEY CLUSTERED ( id )
)
GO
INSERT dbo.system( id, kod, nazwa, priorytet )
VALUES ( 1, N'CRM', N'Dynamix', 10 )
, ( 2, N'FAKT', N'Faktury Etc Limited', 20)
GO
Będziemy również potrzebowali sekwencji, do generowania unikalnych wartości identyfikatorów technicznych w XREF / EDW:
CREATE SEQUENCE edw.SEQ_ID AS BIGINT
START WITH 1
INCREMENT BY 1
MINVALUE -9223372036854775808
MAXVALUE 9223372036854775807
NO CACHE
Mamy więc dwa systemy źródłowe: CRM i FAKT, i z każdego z nich po jednej tabeli w warstwie stage. Zauważmy, że w tabeli pochodzącej z systemu FAKT nazwisko Jana Kowalskiego zostało niechcący przekręcone. Zauważmy też, że system FAKT ma większą wartość w kolumnie [priorytet]. Przyjmiemy, że mniejszy priorytet oznacza pierwszeństwo (a więc system CRM "wygrywa" z systemem FAKT w przypadku, kiedy rekordy dotyczące tego samego klienta przyjdą z obydwu systemów).
W pierwszej kolejności utworzymy sobie tabele w warstwie landing oraz xref:
IF NOT EXISTS ( SELECT * FROM sys.objects WHERE object_id = OBJECT_ID('landing.L_KLIENT') AND type = 'U' )
CREATE TABLE landing.L_KLIENT (
crm_klient_id INT NULL
, crm_klient_imie NVARCHAR(MAX) NULL
, crm_klient_nazwisko NVARCHAR(MAX) NULL
, crm_klient_nr_vat NVARCHAR(50) NULL
, fakt_id INT NULL
, fakt_client NVARCHAR(300) NULL
, fakt_rating CHAR(1) NULL
, fakt_vatno NVARCHAR(20) NULL
, klient_nr_vat NVARCHAR(50) NULL
, klient_nazwa NVARCHAR(300) NULL
, src_system_id SMALLINT NOT NULL
)
GO
IF NOT EXISTS ( SELECT * FROM sys.objects WHERE object_id = OBJECT_ID('xref.X_KLIENT') AND type = 'U' )
CREATE TABLE xref.X_KLIENT (
ID BIGINT NULL
, crm_klient_id INT NULL
, crm_klient_imie NVARCHAR(MAX) NULL
, crm_klient_nazwisko NVARCHAR(MAX) NULL
, crm_klient_nr_vat NVARCHAR(50) NULL
, fakt_id INT NULL
, fakt_client NVARCHAR(300) NULL
, fakt_rating CHAR(1) NULL
, fakt_vatno NVARCHAR(20) NULL
, klient_nr_vat NVARCHAR(50) NULL
, klient_nazwa NVARCHAR(300) NULL
, src_system_id SMALLINT NOT NULL
)
GO
IF NOT EXISTS ( SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID('xref.X_KLIENT') AND name = 'NCI01_X_KLIENT' )
CREATE NONCLUSTERED INDEX NCI01_X_KLIENT ON xref.X_KLIENT(ID, klient_nr_vat, src_system_id)
INCLUDE (klient_nazwa)
GO
Następnie napiszemy sobie procedurę wypełniającą danymi tabelę LANDING.L_KLIENT, za pomocą danych ze stage:
IF OBJECT_ID('landing.pop_l_klient') IS NULL
EXECUTE('CREATE PROCEDURE landing.pop_l_klient AS SELECT 1 dummy;');
GO
ALTER PROCEDURE landing.pop_l_klient
AS
SET NOCOUNT ON
DELETE FROM landing.L_KLIENT
WHERE src_system_id = 1
INSERT INTO landing.L_KLIENT
( crm_klient_id
, crm_klient_imie
, crm_klient_nazwisko
, crm_klient_nr_vat
, klient_nr_vat
, klient_nazwa
, src_system_id
)
SELECT sck.klient_id
, sck.klient_imie
, sck.klient_nazwisko
, sck.klient_nr_vat
, sck.klient_nr_vat
, sck.klient_imie + ' ' + sck.klient_nazwisko
, sck.src_system_id
FROM stage.s_crm_klient sck
DELETE FROM landing.L_KLIENT
WHERE src_system_id = 2
INSERT INTO landing.L_KLIENT
( fakt_id
, fakt_client
, fakt_rating
, fakt_vatno
, klient_nr_vat
, klient_nazwa
, src_system_id
)
SELECT sfc.id
, sfc.client
, sfc.rating
, sfc.vatno
, sfc.vatno
, sfc.client
, sfc.src_system_id
FROM stage.s_fakt_client sfc
Kolejnym krokiem jest wypełnienie tabeli XREF.X_KLIENT danymi z warstwy landing, z uwzględnieniem (być może) istniejących danych w tabeli docelowej EDW.KLIENT. To najbardziej skomplikowany kawałek logiki: najpierw kopiujemy dane z landing, potem przepisujemy już istniejące ID z EDW, następnie - używając klucza biznesowego (w tym przypadku: numer VAT) - wypełniamy brakujące ID.
IF OBJECT_ID('xref.pop_x_klient') IS NULL
EXECUTE('CREATE PROCEDURE xref.pop_x_klient as SELECT 1 dummy;');
GO
ALTER PROCEDURE xref.pop_x_klient
AS
TRUNCATE TABLE xref.X_KLIENT;
INSERT INTO xref.X_KLIENT
SELECT NULL
, *
FROM landing.L_KLIENT
UPDATE tgt
SET tgt.ID = src.ID
FROM xref.X_KLIENT tgt
JOIN edw.KLIENT src ON src.NR_VAT = tgt.klient_nr_vat;
IF OBJECT_ID('tempdb..#klient') IS NOT NULL
DROP TABLE #klient
SELECT CONVERT(BIGINT, NULL) ID
, xk.klient_nr_vat
INTO #klient
FROM xref.X_KLIENT xk
WHERE xk.ID IS NULL
GROUP BY xk.klient_nr_vat
UPDATE #klient
SET ID = NEXT VALUE FOR edw.SEQ_ID
UPDATE tgt
SET tgt.ID = src.ID
FROM xref.X_KLIENT tgt
JOIN #klient src ON tgt.klient_nr_vat = src.klient_nr_vat
DROP TABLE #klient;
Tu mała uwaga: w przypadku MSSQL niestety nie ma możliwości zapisania danych bezpośrednio z sekwencji do tabeli XREF.X_KLIENT dla więcej niż jednego rekordu (nie można używać NEXT VALUE FOR w przypadku agregacji), dlatego musimy posiłkować się dodatkową tabelą tymczasową #klient. W przypadku Oracle takie ograniczenie nie występuje.
Kolejnym, ostatnim już krokiem, jest zapisanie danych do tabeli EDW.KLIENT:
IF OBJECT_ID('edw.pop_klient') IS NULL
EXECUTE('CREATE PROCEDURE edw.pop_klient as SELECT 1 dummy;');
GO
ALTER PROCEDURE edw.pop_klient
AS
SET NOCOUNT ON
; WITH q1
AS ( SELECT ID
, SUM(src_system_id) src_sys
FROM xref.X_KLIENT
GROUP BY ID) ,
q2
AS ( SELECT src.ID
, src.klient_nr_vat
, src.klient_nazwa
, q1.src_sys
, s.priorytet
FROM xref.X_KLIENT src
JOIN dbo.system s ON src.src_system_id = s.id
JOIN q1 ON src.ID = q1.ID) ,
q3
AS ( SELECT q2.ID
, q2.klient_nr_vat
, q2.klient_nazwa
, q2.src_sys
, q2.priorytet
, ROW_NUMBER() OVER ( PARTITION BY q2.klient_nr_vat ORDER BY q2.priorytet ) rn
FROM q2)
MERGE edw.KLIENT tgt
USING
( SELECT *
FROM q3
WHERE q3.rn = 1 ) src
ON tgt.ID = src.ID
WHEN MATCHED THEN
UPDATE SET
tgt.NR_VAT = src.klient_nr_vat
, tgt.NAZWA = src.klient_nazwa
, tgt.SRC_SYSTEM = src.src_sys
WHEN NOT MATCHED BY TARGET THEN
INSERT
VALUES ( src.ID
, src.klient_nr_vat
, src.klient_nazwa
, src.src_sys
) ;
Dobrze byłoby teraz uruchomić cały ten kod:
EXECUTE landing.pop_l_klient
EXECUTE xref.pop_x_klient
EXECUTE edw.pop_klient
W ten oto sposób otrzymaliśmy kompletne (acz bardzo prościutkie) rozwiązanie EDW, przekształcające "surowe" dane z warstwy stage do "ładnych" danych w warstwie EDW.
Zobaczmy teraz na to całościowo: co siedzi w poszczególnych tabelach po zakończeniu procesu?
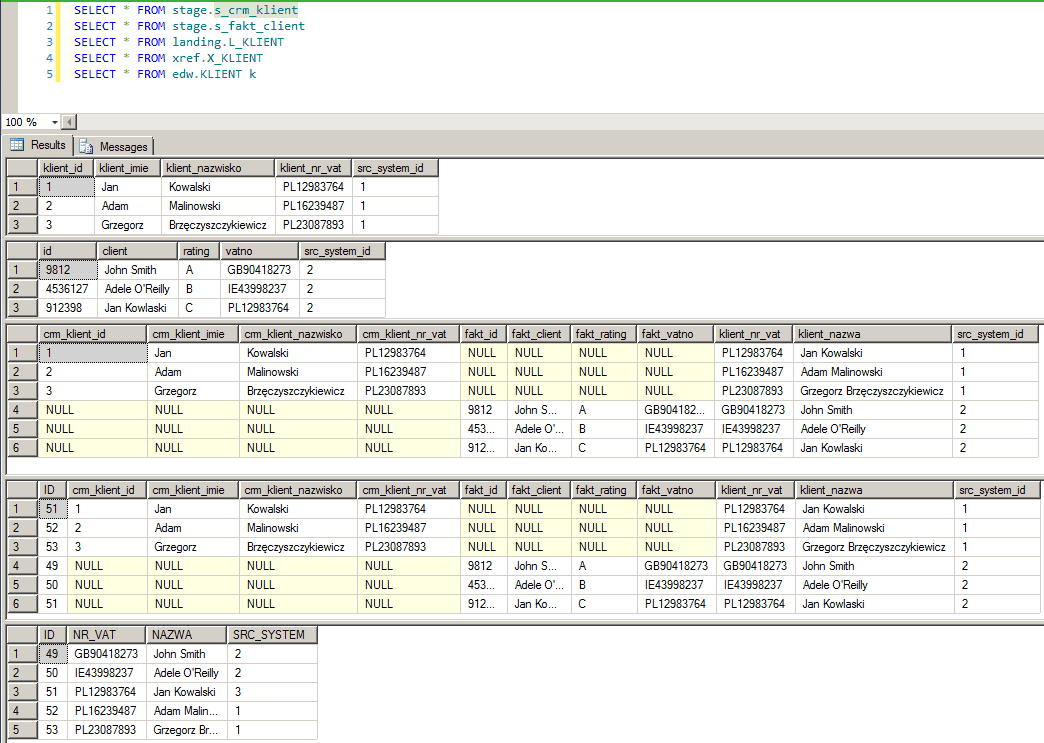
Widzimy na przykład, że w warstwie xref obydwa rekordy Jana Kowalskiego dostały to samo ID (51).
Zróbmy teraz mały eksperyment: zmieńmy priorytety systemów źródłowych w taki sposób, żeby FAKT "wygrywał" z CRM w razie "konfliktu":
UPDATE dbo.system
SET priorytet = 30
WHERE kod = 'CRM'
EXECUTE landing.pop_l_klient
EXECUTE xref.pop_x_klient
EXECUTE edw.pop_klient
SELECT *
FROM edw.KLIENT

Jak widać nazwa "Jan Kowalski" została teraz zastąpiona nazwą "Jan Kowlaski", ponieważ system FAKT "wygrał" z CRM. Przywróćmy rzeczy do "normalności":
UPDATE dbo.system
SET priorytet = 10
WHERE kod = 'CRM'
EXECUTE landing.pop_l_klient
EXECUTE xref.pop_x_klient
EXECUTE edw.pop_klient
SELECT *
FROM edw.KLIENT
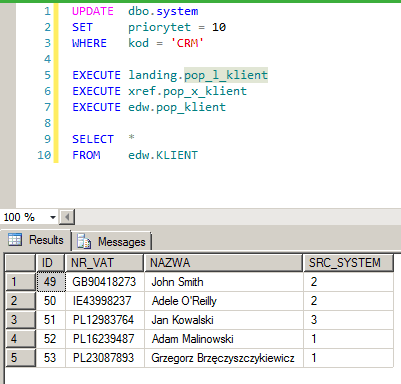
Jak widać sprawy powróciły do "normalności", zgodnie z oczekiwaniem
Za tydzień omówimy sobie przedostatnią warstwę EDW, czyli Data Marts. Stay tuned!
dla NEXT VALUE FOR masz klauzulę OVER – chyba powinno wystarczyć. Sprawdzę [kiedyś]
O, nie wiedziałem. Chwilowo nie mam tego jak sprawdzić, ale z BOL wynika, że OVER w przypadku NEXT VALUE FOR dotyczy wyłącznie kolejności nadawania identyfikatorów. O grupowaniu nic nie ma. Ale sprawdzę i dam znać.