Obróbka tekstu jest trudna. I nie mówię tu o składzie łamane przez poligrafię, bo to całkiem odrębny kosmos jest. Nie. Mówię o podstawowym, zwykłym tekście zapisanym w pamięci komputera w formie pliku .txt tudzież .csv jak kto woli.
(Nawiasem mówiąc całkiem osobnym tematem jest tworzenie edytorów tekstu - mówię tu o kombajnach typu UltraEdit czy Notepad++ itd - tu ilość pułapek, na które programista natrafia, jest niezliczona. Ale o tym może kiedy indziej).
Tekst jaki jest - każdy widzi. Literka. Następna literka. Cyferka. Spacja. Bezmyślnik. I tak dalej…
Z tym, że na świecie jest wiele języków, każdy ma pierdyliony różnych dziwnych znaczków, a jedna literka tradycyjnie już zapisana była na ośmiu bitach, czyli jednym bajcie. A z ośmiu bitów to można wycisnąć maksymalnie 256 różnych różności, z czego spora część i tak odpada bo znaki kontrolne.
Tymczasem sam alfabet chiński to około 50 tysięcy różnych znaczków - co prawda żeby biegle czytać wystarczy opanować około 10% najczęściej używanych, ale to i tak o wiele więcej, niż jesteśmy w stanie wycisnąć z jednego bajtu. A co z innymi alfabetami?
Człowiek myślał myślał - i wymyślił. Skoro nie da się zmieścić wszystkich alfabetów w ośmiu bitach, trzeba dodać więcej bitów na znak.
Tak powstały standardy UTF (a konkretnie UTF-8, UTF-16 oraz UTF-32 i parę innych), które używają maksymalnie do czterech bajtów na jeden znak, dzięki czemu przestrzeń znaków rozciąga się teraz na miliardy możliwości i można tam zmieścić nie tylko wszystkie ludzkie alfabety, ale też niezliczone ilości różnych symboli, emotikonek i innych modyfikatorów, o których jednak dziś nie chcę pisać, bo by mi się skończyło miejsce. Temat jest bowiem szeroki jak Jangcy.
Dziś - zgodnie z tytułem - będzie BOM.
BOM czyli po naszemu Byte Order Mark to wredne dwa, trzy, cztery lub (w jednym ekstremalnym przypadku) pięć bajtów, które czasem można znaleźć na samym początku pliku tekstowego. Nie widać ich, nie słychać, a potrafią nieźle namieszać.
Pokażę dziś jak je rozpoznać oraz jak się ich pozbyć.
Po co w ogóle jakiś BOM?
W komputerach jest tak, że jak już powstaje jakiś standard, to zawsze paru wariatów zaproponuje parę wariantów i nie wiadomo który bardziejszy. Na przykład jeżeli standard mówi, że mają być dwa bajty obok siebie, ale nie mówi który bajt jest pierwszy a który drugi, to zaraz się okaże, że jedni te bajty zapiszą sobie od lewej do prawej a drudzy na odwrót i jedni na drugich potem krzyczą, że tamci są gupi i nie powinni w ogóle siadać do klawiatur.
I wtedy do akcji wkracza Microsoft, cały na biało i mówi, że moi drodzy, po co kłótnie, po co wasze swary głupie, i tak jesteście w dupie i tak, więc zamiast się kłócić o to czy pierwszy bajt jest w lewej czy z prawej, postawmy na samym początku pliku specjalny znacznik, który powie czy reszta pliku jest w tę czy we w tę i po rybach.
Znacznik BOM to - w zależności od rodzaju UTF - następujące bajty:
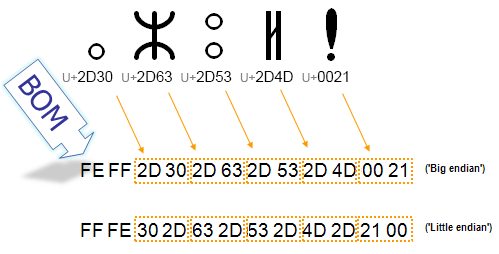
Dla UTF-8 mamy zawsze EF-BB-BF (czyli trzy bajty - niezorientowanym przypominam, że dwa heksy obok siebie to jeden bajt) - nie ma tu różnych wartości BOM, bo w UTF-8 mamy albo znaczki jednobajtowe, albo wielobajtowe od lewej do prawej, koniec.
Dla UTF-16 mamy dwie możliwości: albo FE-FF albo FF-FE. FE-FF jest zarezerwowane dla Big Endian (czyli od lewej do prawej), natomiast FF-FE - dla Little Endian (od prawej do lewej).
Dla UTF-32 (rzadko używany… no ale jest) mamy całkiem podobnie, tylko rozciągnięte na cztery bajty: Big Endian jest 00-00-FE-FF, a Little Endian - FF-FE-00-00.
I tu by się mogła historia skończyć, ale się nie kończy. Są jeszcze różne inne, całkiem już egzotyczne standardy kodowania tekstu i dla nich też zdefiniowane są znaczniki BOM:
- Dla UTF-1 mamy F7-64-4C
- Dla UTF-EBCDIC BOM to DD-73-66-73
- Dla SCSU: 0E-FE-FF
- Dla BOCU-1: FB-EE-28
- Wreszcie dla GB-18030: 84-31-95-33
Koniec?
Nie! Jedyna osada, zamieszkała przez nieugiętych Galów...
Jest jeszcze UTF-7! I tutaj - w zależności od pogody, pory roku, wyznania, preferencji seksualnych lub stosunku do służby wojskowej, BOM może przyjąć jedną z następujących wartości: 2B-2F-76-38, 2B-2F-76-39, 2B-2F-76-2B, 2B-2F-76-2F, 2B-2F-76-38-2D.
Teraz koniec.
Najważniejsze jednak w dzisiejszym wpisie (ktoś do tego miejsca w ogóle dotarł?) jest to, że chociaż BOM jest zjawiskiem dość powszechnym i pozwala wygodnie rozpoznać z jakiego rodzaju kodowaniem tekstu mamy do czynienia w pliku, to jednak wiele programów lub systemów nie uznaje tego wynalazku i jeżeli dostanie do skonsumowania plik rozpoczynający się znacznikiem BOM to albo się od razu zesra, albo nas okrzyczy i każe iść na drzewo (i dopiero potem się zesra).
Dlatego też warto opanować sztukę rozpoznawania i usuwania tego znacznika z pliku.
Najpierw pokażę jak w ogóle rozpoznać czy BOM jest czy go nie ma.
Wydawałoby się - nic prostszego. Otwieramy plik Notatnikiem... I nic. BOM jest bowiem niewidzialny. Standardy UTF mówią, że BOM wygląda jak spacja o zerowej długości. Widział ktoś kiedyś spację o zerowej długości? No właśnie.
Metód ("metodów"?) jest kilku. Najprościej oczywiście za pomocą Total Commandera: najeżdżamy na plik kursorem i naciskamy F3 (podgląd zawartości) i zaraz potem 3 (bez F), co przełącza nas w wyświetlanie binarne - szesnastkowe. O, tak:

Widoczne na samym początku znaczki EF BB BF to BOM standardu UTF-8.
A co jeżeli nie mamy Total Commandera?
Drugą metodą jest użycie Notepad++, który te wszystkie BOM-y i inne tekstowe cudeńka wyssał z mlekiem matki. Otwieramy do edycji plik tekstowy i widzimy na samym dole po prawej:

W tym przypadku nie musimy nawet znać tych wszystkich kombinacji BOM - software rozpozna je za nas i grzecznie poinformuje.
Czasem jednak przydarza się tak, że jesteśmy na korporacyjnej maszynie obwarowanej srogimi ostrokołami firewalli i innych reguł i polityk, nawet krzywo pierdnąć się nie da, co dopiero instalować jakieś Total Commandery czy inne Notepad PlusPlusy. No nie da się i już. Co wtedy?
Wtedy oczywiście trzeba sobie samemu zbudować prosty sprawdzacz, najlepiej przy użyciu narzędzi wbudowanych standardowo w OS. Czyli - jakże by inaczej - na przykład PowerShell, mój ulubiony ostatnio język skryptowy.
Jeżeli nie mamy zablokowanego dostępu do konsoli PowerShell, uruchamiamy konsolę i wpisujemy:
$plik = [System.IO.File]::ReadAllBytes("sciezka/do/naszego/pliku.txt")Powyższe zaklęcie utworzy zmienną $plik i zapisze w niej zawartość całego pliku. Tera z wystarczy sprawdzić co siedzi na początku:
$plik[0..4]Powyższe polecenie wyświetli nam pięć początkowych bajtów naszego pliku, każdy w osobnej linijce:
254 255 0 83 0
254-255 to na szesnastkowy FE-FF czyli UTF-16-BE (Big Endian: kodowanie od lewej do prawej).
Oczywiście jeżeli zamiast Windows mamy maszynkę z Linuksem, sytuacja staje się o wiele prostsza. Tam jest mnóstwo rożnych narzędzi, które potrafią rozpoznawać kodowanie plików. Na przykład polecenie file (z opcją -i) lub ukradnięta od Mozilli komenda uchardet, lub cokolwiek innego. Ale to już może kiedy indziej.
No dobra. Wiemy jak rozpoznać BOM (czyli: czy jest oraz jaki jest konkretnie), teraz nauczymy się jak drania usunąć.
Jeżeli dysponujemy Notepad++, po prostu otwieramy plik do edycji i z menu Encoding wybieramy UTF-8 - w efekcie caly plik zostanie przekodowany do UTF-8 bez znacznika BOM. Niestety, Notepad++ nie umie tego samego manewru powtórzyć dla UTF-16 czy UTF-32, ale przyznajmy szczerze, jak często pracujemy z którymś z tych standardów?
Jeżeli natomiast Notepad++ nie mamy (i mieć nie chcemy / nie możemy), można znów złapać się Powershell-a:
Najpierw wczytujemy plik do zmiennej:
$plik = Get-Content .\test-file.txtPotem tworzymy sobie taki specjalny dynks reprezentujący kodowanie UTF-8 bez BOM:
$bezBOM = New-Object System.Text.UTF8Encoding $FalseWreszcie zapisujemy plik do wersji pozbawionej BOM, używając ww. dynksu:
[System.IO.File]::WriteAllLines("test-file2.txt", $plik, $bezBOM)Powstały w ten sposób plik (tu: test-file2.txt) będzie miał zawartość identyczną z oryginałem z wyjątkiem tego nieszczęsnego BOM.
Na zakończenie wyjaśnię jeszcze po cholerę o tym w ogóle piszę. Otóż jako programista starej daty od zawsze miałem kłopoty z tymi wszystkimi kodowaniami wielobajtowymi - mój pierwszy komputer dostałem w czasach, kiedy królował DOS i kodowanie ANSI (i różne inne jednobajtowe), i tam się uczyłem podstaw programowania i obróbki danych. A te wszystkie UTF-y i inne kodowania wielobajtowe jakoś mi przemknęły koło nosa do czasu, kiedy raz drugi czy trzeci nadziałem się na nie w pracy i musiałem szybciorem sobie poradzić.
Dzięki temu wpisowi usystematyzowałem sobie wiedzę o kodowaniach UTF-*, odwiedziłem też pierdylion stron poświęconych zagadnieniom pokrewnym oraz - być może - pomogłem jakiejś zagubionej duszy rozwikłać problem z BOM.
Smacznego!
pamiętam walkę z BOMem w wymianie z partnerami [FTP + ETL]
Jedna strona nie umiała nie zapisać BOMa, drugiej przeszkadzało to w czytaniu…
Ludzie ludziom ten los zgotowali.
U mnie ostatnio podobnie, stąd właśnie ten wpis.
Ciekawe. To teraz IPv6 😉
Od razu kojarzy mi się NFZ i dzielni programiści dostawcy oprogramowania szpitalnego. NFZ publikuje słowniki, w których chyba
nie zwraca uwagi na zestaw znaków i to samo czynią ci drudzy. W efekcie świadczenie wg NFZ ma w nazwie ’Kwas 3,7,11,15 – tetrametylo heksadekanowy (fitanowy)’ przy czym nie wiadomo, czym jest ta kreska, bo kresek w zestawie jest kilka różnych. Dzielni programiści importują ten słownik, jednocześnie zamawiając dwie pizze XXL, bo jest trzecia w nocy i są głodni. W końcowym efekcie lekarz drukuje kartę informacyjną pacjenta i w świat idzie opis o treści: ’Kwas 3,7,11,15 ? tetrametylo heksadekanowy (fitanowy)’ albo Angiografia bez wzmocnienia kontrastowego ? RM sugerując bezbrzeżne zdumienie lekarza tym, co pacjentowi uczynił…
Bit, bit, bajt, bajt, UTF, Bom…
Kurde to brzmi jak niezła muza Aphex Twina 😀