Ponieważ nie samym SQL-em człowiek żyje...
Chociaż czasem ubolewam, że ludzie mówią tyloma różnymi językami. Jakby tak wszyscy się przestawili na SQL, byłoby dużo prościej.
... żyje, powiadam, spróbowałem ostatnio pobawić się w wizualizację...
A może "we wizualizację"? Skoro jest "we wtorek"? No ale z drugiej strony jednak "w środę" i "w Wiedniu" więc zostaje.
... danych za pomocą Pythona. Normalnie by mi się nie chciało, ale akurat (A) miałem chwilę, bo wszystkie zadania służbowe czekały na jakąś reakcję z drugiej (a czasem i trzeciej) strony, tudzież (B) nawet jeżeli mi się nie chce na stare lata klepać kodu, to mamy teraz LLM-y, za pomocą których można masowo i względnie bezwysiłkowo testować różne jednorazowe pomysły i sprawdzać co z tego wyniknie.
Akurat dostałem automatycznego maila od Numbeo, z linkiem do danych zgromadzonych przez ostatnie dwa lata. Można się stamtąd dowiedzieć mieszkańcy których krajów najczęściej wyszukują jakich innych krajów w serwisie.
Czyli w drugiej pochodnej, do jakich krajów najchętniej chcieliby się przeprowadzić, bo przyszli emigranci to największa grupa tamecznych użytkowników.
Dla każdego kraju "źródłowego" mamy wymienionych 20 najczęściej wyszukiwanych krajów "docelowych", wraz z procentami. Tutaj link.
Dane są wprawdzie opublikowane w formie tekstowej, "do czytania", ale przerobienie tego na proste, trzykolumnowe CSV zajęło mi z pomocą LLM mniej więcej tyle czasu, co napisanie tego akapitu:
import csv
import re
input_file = "destinations.txt"
output_file = "destinations.csv"
data = []
with open(input_file, "r", encoding="utf-8") as file:
source_country = None
for line in file:
line = line.strip()
match = re.match(r"(.+?)'s Top Destination Searches", line)
if match:
source_country = match.group(1)
continue
if not line:
continue
if source_country:
destination_data = line.split(" - ")
if len(destination_data) == 2:
destination_country = destination_data[0].strip()
percentage = destination_data[1].replace("%", "").strip()
data.append([source_country, destination_country, percentage])
with open(output_file, "w", newline="", encoding="utf-8") as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(["source_country", "destination_country", "percentage"])
csv_writer.writerows(data)
Jeżeli chcesz spróbować, ściągnij sobie do pliku destinations.txt dane z powyższego artykułu, począwszy od linijki "Albania's Top Destination Searches" aż do ostatniej, dwudziestej pozycji w bloku "Vietnam's Top Destination Searches". Plik powinien mieć dokładnie 2169 linii.
Wykonanie powyższego kodu wypluje nam plik destinations.csv, z trzema kolumnami: source_country, destination_country, percentage. Od tej pory będziemy używać tego właśnie pliku do dalszych eksperymentów.
Jako wielki fan grafów postanowiłem zacząć od GraphViz, technologii, której wiek liczy się już w interglacjałach. A więc kolejny skrypt przekształcający nasze csv na dot.
import csv
input_csv = "destinations.csv"
output_dot = "destinations.dot"
edges = []
with open(input_csv, 'r', encoding='utf-8') as csvfile:
csv_reader = csv.reader(csvfile)
next(csv_reader)
for row in csv_reader:
source_country, destination_country, percentage = row
edges.append((source_country, destination_country, percentage))
with open(output_dot, 'w', encoding='utf-8') as dotfile:
dotfile.write("digraph CountrySearches {\n")
dotfile.write(" rankdir=LR;\n") # Optional: sets layout from left to right
dotfile.write(" node [shape=ellipse];\n\n")
for source, destination, percentage in edges:
dotfile.write(f' "{source}" -> "{destination}" [label="{percentage}%"];\n')
dotfile.write("}\n")
Pomysł zacny. Wykonanie... no cóż. Pacjent przeżył, ale co to za życie. Wyrenderowałem ten plik za pomocą fdp, sfdp, twopi, neato... Efekty poniżej:

FDP
SFDP
TWOPI
NEATO
Na koniec spróbowałem jeszcze domyślnego DOT, zaczął mielić i zrobiła się pora lunchu, zostawiłem więc otwartą konsolę i udałem się na posiłek.
Po powrocie dalej sie mieliło, zostawiłem w tle - w końcu po godzinie i czterdziestu minutach (!) wypluł plik png o rozmiarze ciut ponad 100 MB. Nie będę tu wrzucał oryginału, bo mi szkoda miejsca na serwerze z blogiem. Poniżej zoom 3%:

Oczywiście przy zbliżeniu 100% wszystko jest ładnie czytelne:
No ale tak to se można. Żeby to miało jakiś sens, potrzebowałbym monitora o przekątnej co najmniej trzy metry oraz rozdzielczości ponad 25K pikseli w każdą stronę. Nidyrydy.
No dobra. Skoro GraphViz nie podołał, trzeba odwiesić aureolę na gwóźdź i zaprzyjanić się z jakimiś bardziejszymi cosiami. Żeby nie czuć się jak zdrajca (GraphViz to technologia, z którą znamy się jak łyse konie od bardzo dawna), spróbowałem jeszcze ograniczyć listę krajów docelowych do trzech najbardziej popoularnych dla każdego kraju. Tu już nie musiałem czekać zbyt długo i po paru sekundach dostałem plik o rozdzielczości 2026 x 6757 px. Nadal za duży do celów praktycznych, ale przynajmniej coś już trochę widać.
Całość: zoom 14%
Fragment, zoom 48%:
Odłożywszy GraphViz na stronę zacząłem się bawić wizualizacjami wbudowanymi w samego Pythona. Czyli Matplotlib, Seahorse i różne inne, podobne.
Zacząłem od mapy cieplnej:
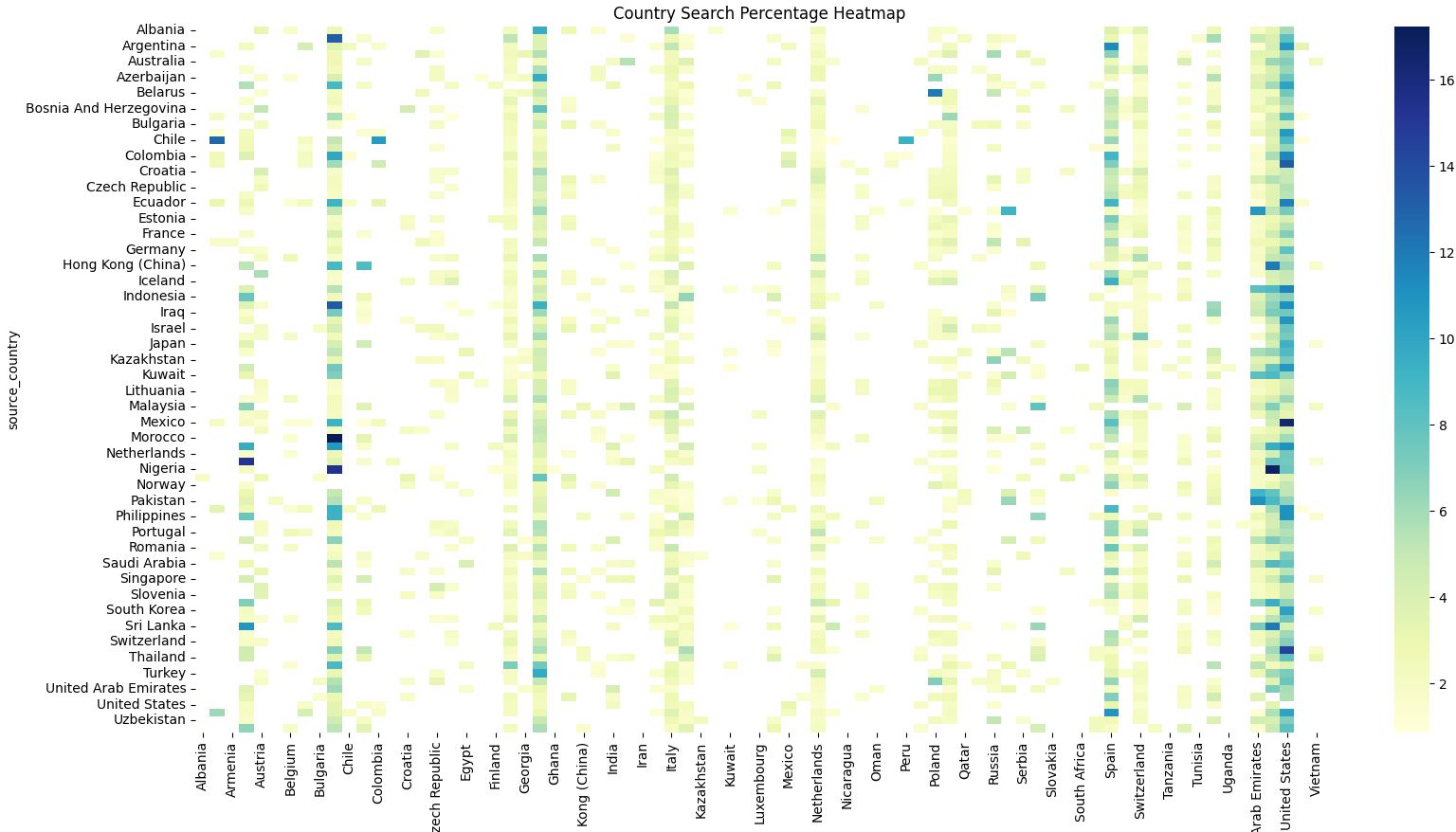
Niby fajna, ale jakoś mało informacjonośna. Acz zdecydowanie lepsza od bazgrołów z smnego początku wpisu 🙂
Potem spróbowałem słupków, ale wynik - chociaż w miarę czytelny - dupy nie urywa:
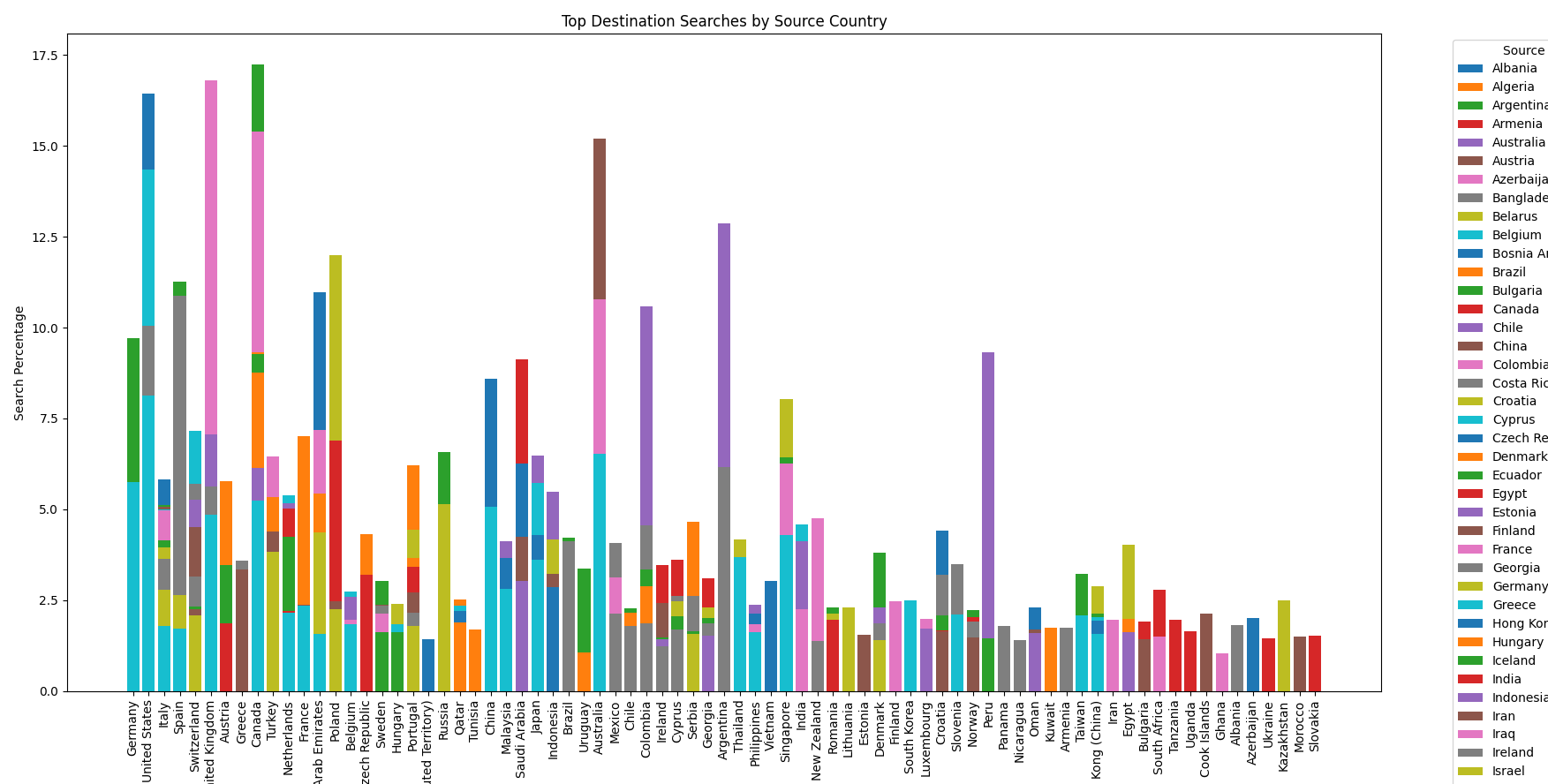
Potem całkiem niechcący udało mi się wyprodukować takie coś:
Wygląda może i ładnie, ale pożytku z tego nie ma żadnego. Przerzuciłem się więc na bąbelki:
Gdyby nie zbyt gęsto upakowane etykiety na osi pionowej, może mielibyśmy zwycięzcę. Chociaż nie, bo kolor bąbelka powinien w teorii pokazywać coś innego niż jego rozmiar, a tutaj jedno z drugim idzie w parze.
Bo praktyka zgadza się z teorią tylko teoretycznie, bo w praktyce to już niekoniecznie.
Na chwilę opuściłem świat Matplotlib i przerzuciłem się na Plotly, z takim oto efektem:

Ładne? Ładne. Pożyteczne? Hmmm.
Kolejny eksperyment polegał na zrobieniu osobnego wykresu dla każdego kraju docelowego a nastęnie poukładaniu tych wszystkich wykresów obok siebie. Efekt jest godny pożałowania:
Za gęsto. Może trzeba się ograniczyć tylko do pięciu najpopularniejszych krajów docelowych?
Paskudztwo. Ale poszedłem za tą myślą i zrobiłem prosty wykres słupkowy pokazujący trzy najpopularniejsze destynacje dla każdego kraju:
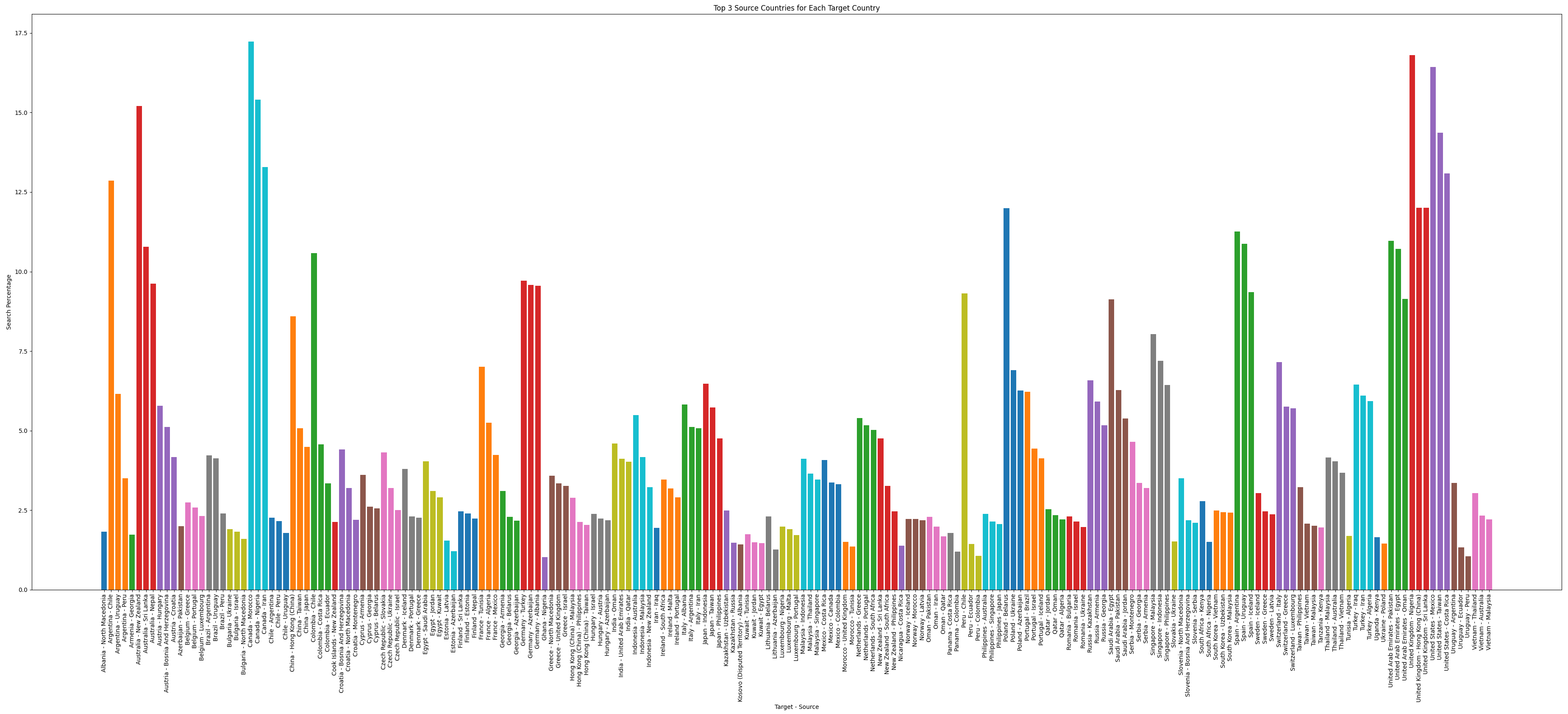
Ładne, czytelne, użyteczność trochę kuleje. Trzeba każdy kraj poskładać do jednego słupka:
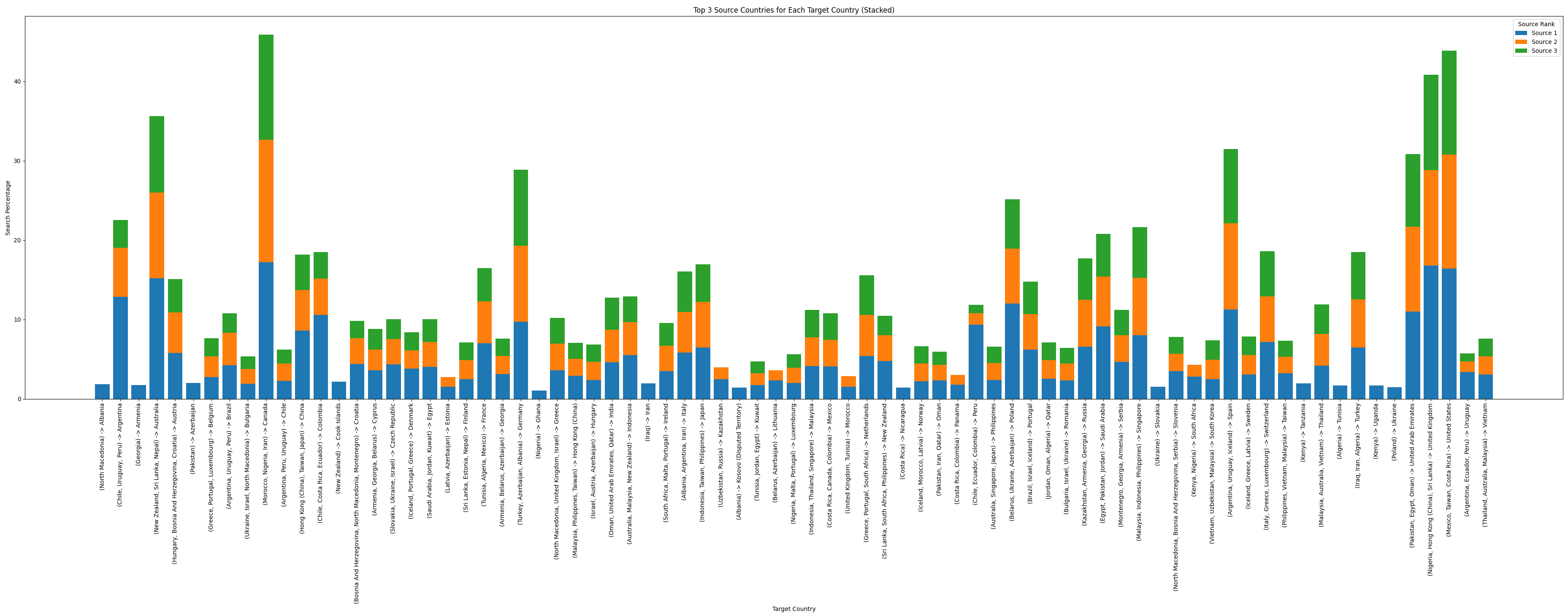
Zaczyna to nabierać jakiegoś sensu. Jeszcze posortować po wysokości słupka...
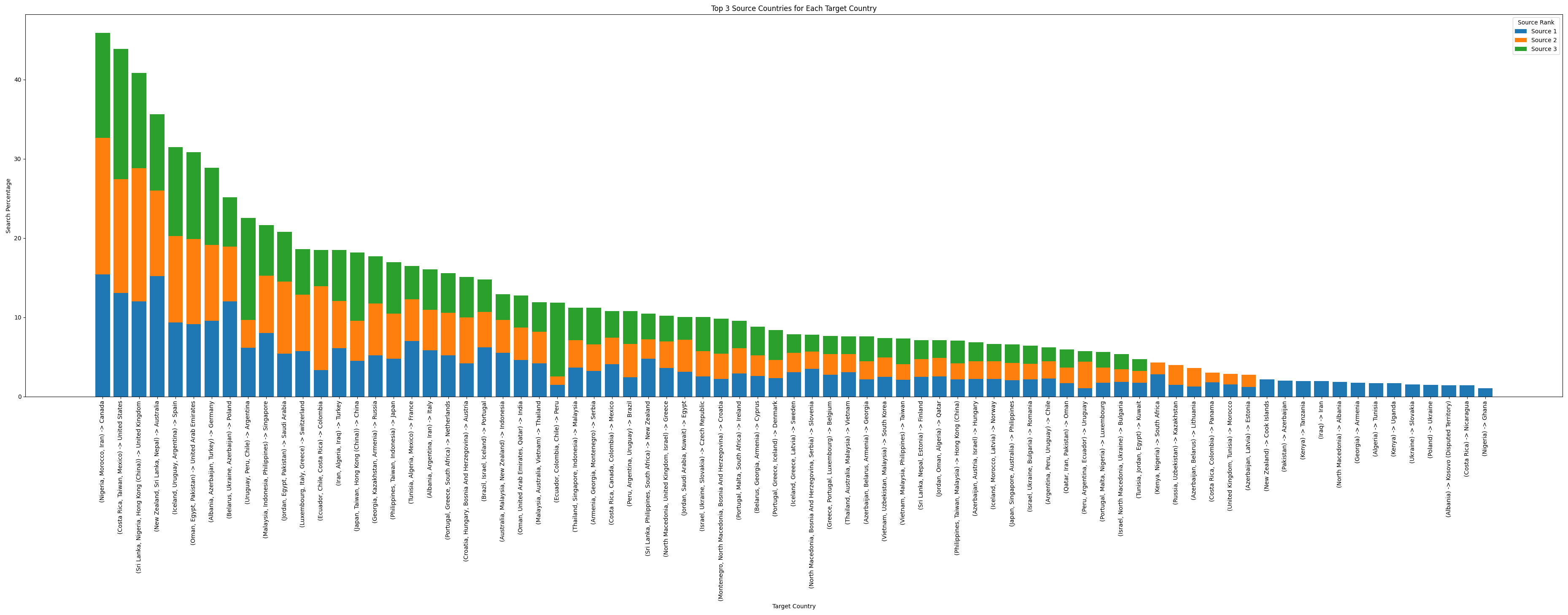
A może zamiast top 3 zrobić top 5?
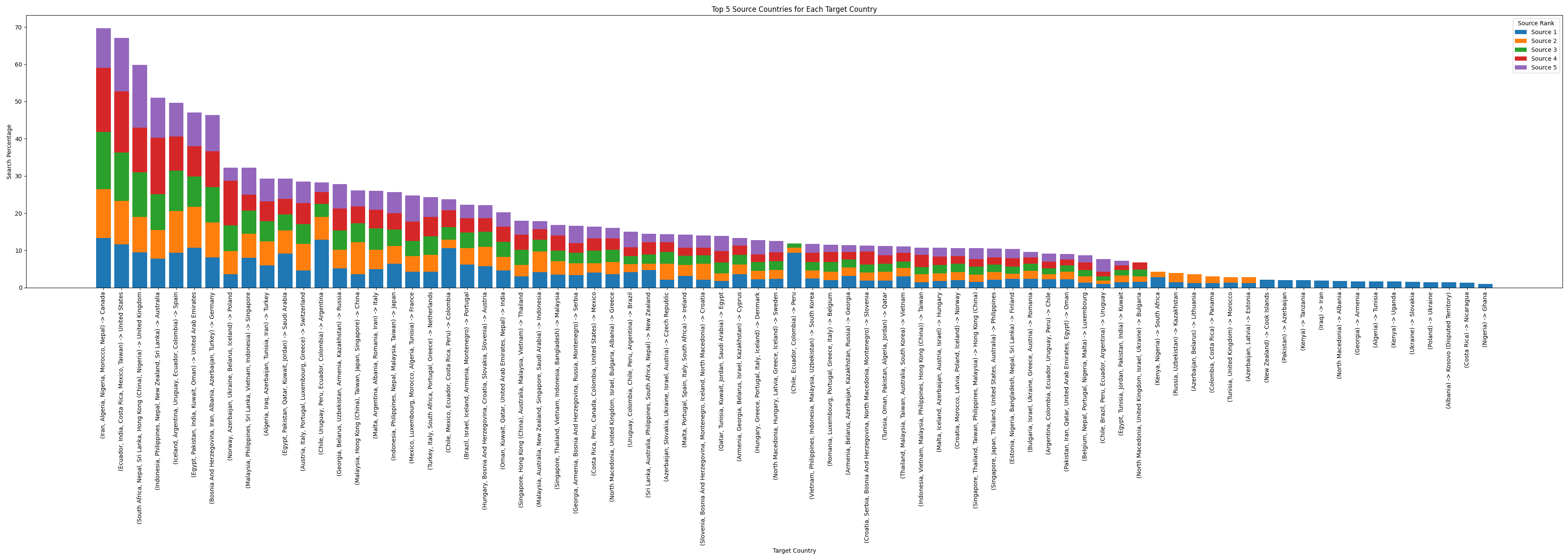
I tutaj skończył mi się rozpęd. Spróbowałem jeszcze na koniec zrobić sobie zestawienie które kraje są najpopularniejsze pod względem liczby krajów źródłowych (z ponimięciem procentów). Wyszło mi takie coś:
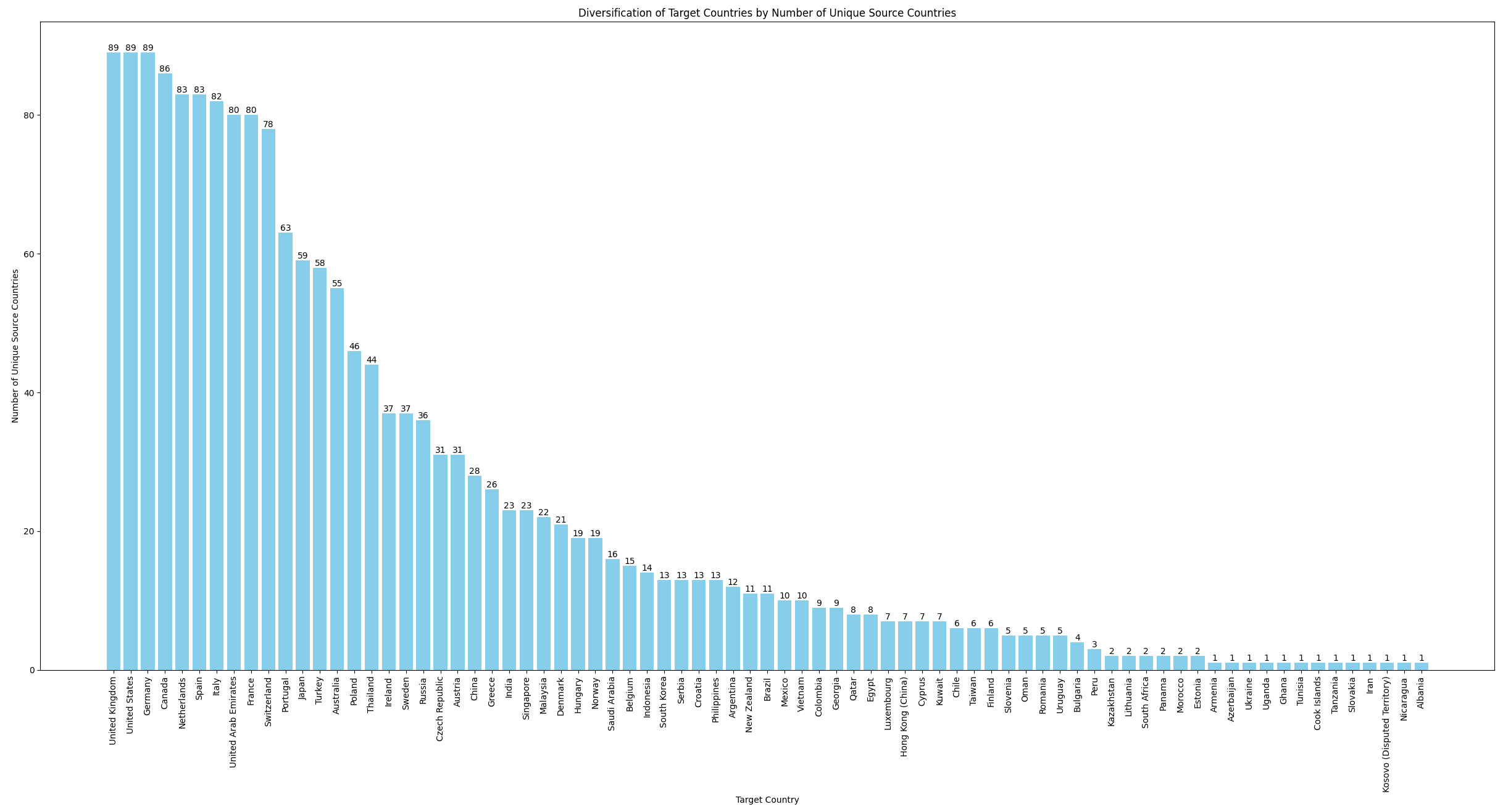
Polska była wyszukiwana przez obywateli 46 różnych krajów. Ha.
Potem jeszcze przez moment spróbowałem zrobić mapę cieplną z płynnymi gradientami (czyli żeby nie było widać linii między wierszami i kolumnami), ale poległem i zakończyłem ćwiczenie.
Jestem ciekaw co jeszcze można by tutaj spróbować zrobić, żeby to ładnie zwizualizować.
Jakieś pomysły?
Hmmm.
Jeżeli chcesz do komentarza wstawić kod, użyj składni:
[code]
tutaj wstaw swój kod
[/code]
Jeżeli zrobisz literówkę lub zmienisz zdanie, możesz edytować komentarz po jego zatwierdzeniu.