
Tytuł dzisiejszego wpisu, gdyby go potraktować poważnie, mógłby brzmieć:
"Jak wykonać zapytanie SQL na danych w formacie XML i po co?"
Ale ponieważ to nie jest poważny blog, zostawię jak jest.
No więc, o sssso chozzzzi?
Chozzzi o tę nieszczęsną technologię przechowywania danych, która - pomimo swych niedoskonałości - zdołała się utrzymać na powierzchni, a nawet zdominować niektóre obszary świata IT- i żyje sobie w najlepsze. Mówię o XML-u.
Jeżeli ktoś jeszcze nie słyszał starego przysłowia pszczół o XML-u, teraz ma okazję:
"XML is like violence. If it doesn't work for you, you're not using enough of it.
Nie lubię XML-a z dwóch powodów: po pierwsze, jest strasznie rozwlekły. Zapisanie kilku bajtów danych w XML-u wymaga kilkukrotnie większej ilości danych kontrolnych. Przy większej ilości danych oraz rozsądnym gospodarowaniu długością znaczników można ów procentaż nieco zmniejszyć, ale w dalszym ciągu mamy do czynienia z całkiem sporym "narzutem protokołu". Drugi aspekt XML-a, którego nie znoszę jeszcze bardziej, to brak jednolitości składni: tę sama informację możemy w XML zapisać na kilka różnych sposobów, co teoretycznie jest fajne (lubimy elastyczność!), ale w praktyce prowadzi do bałaganu. Na przykład dane typu identyfikator / imię / nazwisko mogą być zapisane tak:
<osoba><id>177436</id><imie>Adam</imie><nazwisko>Kowalski</nazwisko></osoba>
... lub tak:
<osoba id="177436" imie="Adam" nazwisko="Kowalski"></osoba>
... lub tak:
<osoba id="177436"><imie>Adam</imie><nazwisko>Kowalski</nazwisko></osoba>
... lub tak:
<osoba id="177436"><imie value="Adam"></imie><nazwisko value="Kowalski"></nazwisko></osoba>
I tak dalej. Taka niejednolitość powoduje zwiększenie złożoności języków wykonywania zapytań do takich danych (tak, języków, jest ich więcej niż jeden!), a także utrudnia analizę danych i ogólnie komplikuje życie programiście, który ma takimi danymi żonglować.
No ale, jak to mówią, jak się nie ma, co się lubi, to się na pochyłe drzewo skacze, dopóki się ucho nie urwie. Mamy XML, będziemy żonglować XML. Trudno.
Zobaczmy teraz, w jaki sposób można do danych w formacie XML wykonywać zapytania SQL. Użyjemy SQL-a od Microsoftu, bo akurat taki mam pod ręką, ale zapewniam, że większość pozostałych wiodących silników baz danych również radzi sobie z danymi XML, w całkiem podobny (żeby nie użyć zbyt długiego słowa: analogiczny) sposób.
Zaczniemy od zdefiniowania danych wejściowych:
<?xml version="1.0"?>
<Osoby>
<Osoba id="1">
<Imie>Adam</Imie>
<Nazwisko>Kowalski</Nazwisko>
</Osoba>
<Osoba id="2">
<Imie>Jan</Imie>
<Nazwisko>Kosiarz</Nazwisko>
</Osoba>
<Osoba id="3">
<Imie>Janina</Imie>
<Nazwisko>Michalska</Nazwisko>
</Osoba>
</Osoby>
Powyższe dane w formacie XML reprezentują niedużą tabelkę o nazwie Osoby, z trzema kolumnami (id, nazwisko, imie) i trzema rekordami. Spróbujmy teraz dobrać się do tych danych za pomocą SQL-a:
DECLARE @dane_xml XML = '<?xml version="1.0"?> <Osoby> <Osoba id="1259"> <Imie>Adam</Imie> <Nazwisko>Kowalski</Nazwisko> </Osoba> <Osoba id="2532"> <Imie>Jan</Imie> <Nazwisko>Kosiarz</Nazwisko> </Osoba> <Osoba id="6433"> <Imie>Janina</Imie> <Nazwisko>Michalska</Nazwisko> </Osoba> </Osoby>';
Najpierw coś prostego: spróbujmy wyciągnąć pojedynczy rekord z tej gmatwaniny:
select @dane_xml.value('(/Osoby/Osoba/@id)[1]','nvarchar(max)') as id
, @dane_xml.value('(/Osoby/Osoba/Imie)[1]','nvarchar(max)') as imie
, @dane_xml.value('(/Osoby/Osoba/Nazwisko)[1]','nvarchar(max)') as nazwisko;
Powyższe zapytanie SQL zwróci jeden rekord z trzema kolumnami:

Proszę zwrócić uwagę na to, w jaki sposób podajemy lokalizację elementu XML:
/Osoby/Osoba/@id
/Osoby/Osoba/Imie
I tak dalej. Taka składnia nazywa się XPath i jest dość rozbudowana (chętnych oraz samobójców zapraszam na Google po więcej szczegółów). Zaletą XPath jest to, że nie musimy się bawić w XSLT, przy którym XML jest prosty i klarowny 😉 W naszym przypadku wyciągamy wartość atrybutu ID oraz wartości dwóch węzłów: Imie oraz Nazwisko.
Jeżeli chcemy znaleźć rekord o znanym ID, robimy tak:
select @dane_xml.value('(/Osoby/Osoba[@id=''6433'']/@id)[1]','nvarchar(max)') as id
, @dane_xml.value('(/Osoby/Osoba[@id=''6433'']/Imie)[1]','nvarchar(max)') as imie
, @dane_xml.value('(/Osoby/Osoba[@id=''6433'']/Nazwisko)[1]','nvarchar(max)') as nazwisko;
Wynik:

W tym przypadku użyliśmy składni Pole[@atrybut='wartość'], która wyszuka nam wszystkie rekordy o tej wartości atrybutu.
Dociekliwy Czytelnik zauważy jeszcze na końcu zapytania wyrażenie "[1]" - jest to numer kolejny rekordu, który chcemy zwrócić. W pierwszym przykładzie możemy użyć [1], [2] lub [3], ponieważ mamy trzy rekordy typu Osoba. W drugim przykładzie, ponieważ szukamy konkretnego rekordu (o id=6433), zadziała tylko [1], bo więcej rekordów o takim id nie ma.
No dobrze. Wiemy już, jak znaleźć pojedynczy rekord i go wyświetlić w postaci tabeli. A co, jeżeli chcemy z takiego XML-a wyciągnąć więcej rekordów?
Tu w sukurs przychodzi metoda .nodes() obiektu XML, która zwraca wiele rekordów, a nie tylko jeden.
O, tak:
select osoba.c.value('@id', 'nvarchar(max)') as id
, osoba.c.value('(Imie)[1]', 'nvarchar(max)') as imie
, osoba.c.value('(Nazwisko)[1]', 'nvarchar(max)') as nazwisko
from @dane_xml.nodes('Osoby') as osoby(c)
outer apply osoby.c.nodes('Osoba') as osoba(c);
Wynik powyższego zapytania wygląda tak:
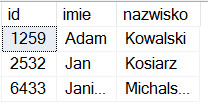
Szczegółowej składni powyższego zapytania już mi się dziś nie chce szczegółowo omawiać. W skrócie: @dane_xml.nodes() zwraca wszystkie rekordy, a osoby.c.nodes(...) zwraca wszystkie kolumny dla każdego rekordu. O wyrażeniu OUTER APPLY być może napiszę kiedy indziej - jest to dość potężne narzędzie języka SQL, które - używane z głową - daje całkiem ciekawe możliwości.
jakby to kolega translatnal, to by bylo easier pokazac mniej dzikim tribes 😉
Jakbym to translatnął, to bym musiał sam zrozumieć zagadnienie najpierw :]