Zagadka jest w sumie całkiem prosta, jeżeli zaprzęgnie się do jej rozwiązania komputer i każe przeszukać wszystkie kombinacje.
Ja zrobiłem coś takiego:
def następna_liczba(n):
return (n*n) // 100 % 10000
def policz_ciąg(n):
wynik = []
while n not in wynik:
wynik.append(n)
n = następna_liczba(n)
return wynik
def znajdź_najdłuższy_ciąg():
najdłuższy = 0
for i in range(10000):
ciąg = policz_ciąg(i)
if (len(ciąg) > najdłuższy):
wynik = ciąg
najdłuższy = len(ciąg)
return wynik
najdłuższy_ciąg = znajdź_najdłuższy_ciąg()
print(f"Najdłuższy ciąg ma {len(najdłuższy_ciąg)} liczb:", ', '.join(str(x) for x in najdłuższy_ciąg))
Przy okazji zauważamy jak łatwo jest zrobić wyciąganie czterech środkowych cyfr z liczby ośmiocyfrowej nawet wtedy, kiedy nie mamy liczby ośmiocyfrowej ani czterech cyfr do wyciągnięcia: (n*n) // 100 % 10000. Dzielenie całkowite przez sto obcina dwie najmniej znaczące cyfry (po prawej), natomiast dzielenie modulo 10000 wywala z tego co zostało wszystko z wyjątkiem ostatnich czterech cyfr. Poza prostotą podejście to jest bardzo szybkie ze względu na brak konieczności konwersji między liczbami a tekstem.
Po uruchomieniu, skrypt wypluwa:
Najdłuższy ciąg ma 111 liczb: 6239, 9251, 5810, 7561, 1687, 8459, 5546, 7581, 4715, 2312, 3453, 9232, 2298, 2808, 8848, 2871, 2426, 8854, 3933, 4684, 9398, 3224, 3941, 5314, 2385, 6882, 3619, 971, 9428, 8871, 6946, 2469, 959, 9196, 5664, 808, 6528, 6147, 7856, 7167, 3658, 3809, 5084, 8470, 7409, 8932, 7806, 9336, 1608, 5856, 2927, 5673, 1829, 3452, 9163, 9605, 2560, 5536, 6472, 8867, 6236, 8876, 7833, 3558, 6593, 4676, 8649, 8052, 8347, 6724, 2121, 4986, 8601, 9772, 4919, 1965, 8612, 1665, 7722, 6292, 5892, 7156, 2083, 3388, 4785, 8962, 3174, 742, 5505, 3050, 3025, 1506, 2680, 1824, 3269, 6863, 1007, 140, 196, 384, 1474, 1726, 9790, 8441, 2504, 2700, 2900, 4100, 8100, 6100, 2100
Tak więc poprawna odpowiedź brzmi: 6239, 111
A jak Wam poszło?
1
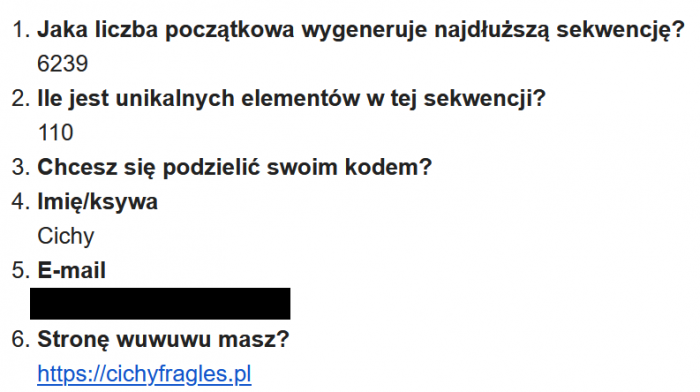
Jeszcze tego samego dnia pierwszą odpowiedź nadesłał Cichy Fragles. Bardzo chętnie bym mu zaliczył, ale się walnął o jeden w liczeniu elementów ciągu i zamiast 111 napisał 110. Zasadniczo mógłbym przyjąć, że 110 to indeks ostatniego elementu i wtedy by przeszło. Hmmm. Zaliczam na pomarańczowo 🙂
2
Również tego samego dnia, o jakiejś nieprzyzwoicie późnej porze, Waldek znalazł dwa rozwiązania po 68 elementów każde. Nie zaliczam.

3
Pierwsze stuprocentowo poprawne rozwiązanie nadesłał dwa dni później Rozie, wraz z niewielkim skryptem w Pythonie. Gratuluję.

seq = {}
def square(n):
result = int(str(n**2).zfill(8)[2:6])
return(result)
for start in range(1, 10000):
seq[start] = [start]
stop = False
curr = start
count = 1
while not stop:
next = square(curr)
if next not in seq[start]:
seq[start].append(next)
count += 1
else:
stop = True
curr = next
longest = 0
value = 0
for i in range(1000, 10000):
if len(seq[i]) >= longest:
value = i
longest = len(seq[i])
print(value, longest)
print(seq[value])
4
Nazajutrz poprawne rozwiązanie przysłał Butter, wraz z następującym skryptem:
_max = 10000
def fn(x):
kw = '{:08d}'.format(x*x)[2:6]
return int(kw)
max_len = 0
max_arr = []
def setPrint(x, arr):
global max_arr
global max_len
max_arr = arr
max_len = len(arr)
print('For {0} len {1} '.format(x, max_len), end = ' => ')
for pos in max_arr:
kw = '{:04d}'.format(pos)
print(kw,end =', ')
print('\n---')
for x in range(0,_max):
rob = [x]
kw = fn(x)
while kw not in rob:
rob.append(kw)
kw = fn(kw)
if len(rob)>max_len:
setPrint(x, rob)
5
W poniedziałek około południa poprawną odpowiedź nadesłał Tywan, który jako pierwszy rozwiązał zagadkę inaczej niż Pythonem (poniżej jego kod w Ruby). Warto również zauważyć, że Tywan jako pierwszy z rozwiązujących poradził sobie z obcinaniem skrajnych cyfr bez konwertowania na tekst i z powrotem.
def solve(n)
seq = []
until seq.include?(n)
seq << n
sq = n * n
n = (sq / 100) % 10_000
end
seq
end
ary = Array.new(10_000){|n| solve(n)}
maxLen = ary.max {|a, b| a.length <=> b.length}.length
p maxLen
(0..9999).each{|n|
v = ary[n]
p n, v if v.length == maxLen
}
6
We wtorek tuż przed północą poprawne rozwiązanie przysłał Krzysiek. Metoda - nieznana.

P.S. Temat można rozciągnąć jeszcze bardziej, na przykład sprawdzić ile różnego rodzaju pętli możemy dostać. Okazuje się, że startując od każdej z 10000 liczb, lądujemy zawsze w jednej z 17 różnych pętli, z których najciekawsza to 3792 => 3792, ponieważ 37922=14379264, co po obcięciu skrajnych czterech cyfr daje... 3792 😉
A jeżeli ktoś jest zainteresowany jak wygląda graf zależności między tymi wszystkimi liczbami, to proszę bardzo.
(swoją drogą jeżeli ktoś ma lepszy pomysł na narysowanie tego grafu, proszę dać znać)
czym robiłeś graf?
Komputerem 😉
A tak na serio to wygenerowałem sobie w Pythonie listę wyrażeń „x->y” dla wszystkich x od 0 do 9999 i wrzuciłem to do pliku .dot jako graf skierowany (czyli digraph g {…}), a potem eksperymentowałem z sfdp, circo, twopi, dot itd. itd. aż znalazłem w miarę sensownie wyglądający układ. Na koniec kazałem mu to wyeksportować do svg, bo formaty rastrowe padały jak muchy.
Wyciąganie środkowych cyfr faktycznie bardzo zgrabne, ale nie tu upatrywałbym pola do optymalizacji. Spodziewałem się, że będzie złożone obliczeniowo. 10k początkowych po maksymalnie 10k w każdym niby ma potencjał na długie liczenie. Dlatego pierwsze co przyszło mi do głowy to zapamiętywanie długości ciągów dla już policzonych początkowych liczb. Potem, przy liczeniu, sprawdzanie, czy przypadkiem nowy wynik nie jest już początkiem policzonego, jeśli tak, dodawanie znanego już wyniku. Pewnie z lru_cache też ładnie by zadziałało.
Jednak już przy testach okazało się, że liczy na tyle szybko, że nie ma sensu optymalizować. W ogóle pętla:
for i in range(0, 10000): for j in range(0, 10000): t = i*jTo raptem kilka sekund na wykonanie.
Zatem: gdzie trudność? Poza off by one. 😉 Myślę, czy przy liczbach 5 albo 6 cyfrowych i odrzucaniu 2 początkowych z wyniku oraz odpowiedniej ilości końcowych nie byłoby ciekawiej.