Jako że od wielu lat "siedzę" w branży Business Intelligence, mam po drodze do czynienia z najprzeróżniejszymi, czasem dość ciekawymi zagadnieniami, składającymi się na ową tajemniczą "Inteligencję".
Dziś opiszę - proszę się nie obawiać, tylko po łebkach i ogólnikowo - co udało mi się niedawno zaobserwować przy okazji ładowania dużych ilości danych XML do hurtowni.
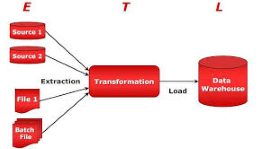
Otóż jakiś czas temu - będzie z rok, a może trochę mniej - zbudowałem dla jednego z moich klientów proces, który najpierw, w pętli, ściąga ze strony internetowej zewnętrznego dostawcy dużo plików XML (za pomocą webservice), a następnie ładuje każdy z tych plików do warstwy STAGE hurtowni danych, gdzie następnie podlegają one dalszej obróbce.
Jak załadować plik XML do tabeli?
Podejście, jakie oryginalnie przyjąłem, było takie, że w pakiecie SSIS utworzyłem sobie (za pomocą skryptu C#.NET) pętlę iterującą po wszystkich plikach XML w folderze z bieżącej sesji, następnie każdy z tych plików wczytywałem (za pomocą innego skryptu C#.NET) do zmiennej tekstowej, której potem używałem w wywołaniu procedury TSQL ładującej te dane do tabeli na serwerze. Interpretacja XML-a odbywa się już wewnątrz procedury TSQL. I działało to całkiem zgrabnie.
Ostatnio jednak, przy całkiem innej okazji, natrafiłem na ten oto artykuł:
http://www.sqlservercentral.com/articles/SQLCLR/65656/
Jest tam przedstawiona prościutka funkcja CLR listująca zawartość folderu. Skopiowałem ją sobie i zacząłem kombinować, do czego by jej użyć.
Okazuje się, że można za jej pomocą bardzo sprawnie ładować dane z plików tekstowych bezpośrednio do bazy SQL, z całkowitym pominięciem technologii SSIS!
Innymi słowy, najpierw listujemy sobie wszystkie pliki, potem - używając OPENROWSET(BULK...) - ładujemy zawartość każdego pliku do lokalnej zmiennej typu XML, a na koniec wyodrębniamy z tej zmiennej wszystkie niezbędne elementy danych i zapisujemy je do docelowej tabeli.
Okazuje się, że takie podejście poskutkowało - w moim konkretnym przypadku - prawie dziesięciokrotnym przyspieszeniem ładowania danych. Zaskoczenie moje było wielkie, bo przecież nie wprowadziłem tu jakiejś jakościowej zmiany - ot, pozbyłem się tylko jednej technologii z łańcucha zdarzeń. Spodziewałem się maksymalnie dwukrotnego przyspieszenia (bo zamiast mieć dwie kopie zmiennej w pamięci, teraz mam tylko jedną) - a tu masz ci los, zamiast 12 plików na minutę teraz ładuje mi się prawie 100.
Dziwny świat...
Tak sobie przypomniałem moje stare zabawy [20040 – wyciąganie xml z maili ;). Taką komunikację miałem z Energisem. XP_ rulez
WHILE @STATUS = 0
BEGIN
EXEC @STATUS = MASTER..XP_FINDNEXTMSG @MSG_ID = @MESSAGE_ID OUTPUT
IF @NEWEST_MAIL = ” AND @MESSAGE_ID ” SET @NEWEST_MAIL = @MESSAGE_ID
IF @MESSAGE_ID @TOP_MAIL
BEGIN
EXEC MASTER..XP_READMAIL @MSG_ID = @MESSAGE_ID, @TYPE = @TYPE OUTPUT,
@SUBJECT =@SUBJECT OUTPUT, @MESSAGE = @MESSAGE OUTPUT,
@ORIGINATOR_ADDRESS =@ORIGINATOR OUTPUT
—
IF @SUBJECT = 'ZADANIA_ToIP’ AND @MESSAGE LIKE '%|[Deimos- mod:El]%’ ESCAPE '|’
BEGIN
SELECT 'PROCESSING: '+@MESSAGE_ID [INFO]
EXEC MASTER..SP_XML_PREPAREDOCUMENT @IMSG OUTPUT, @MESSAGE
UPDATE USL_WYK_TEL_INFO
SET –REM BY MCI: TI_TOIP_DANE = @GW_DEF+”,
TI_TOIP_GATEWAY_USER = NULL,
TI_TOIP_GATEWAY_DATE = NULL,
TI_TOIP_DATA_COMPLET = NULL,
TOIPMAILRET_ID = SEQ_ANS_NR,
TI_WYP = '[RET_ID=’+SEQ_ANS_NR+’]’
FROM
OPENXML(@IMSG, '/TELEFONY[@WERSJA=”1″]/TEL’,0)
WITH(NR VARCHAR(20) '@NR’ ,
PORT VARCHAR(255) '@PORT’,
LINK VARCHAR(255) '@LINK’,
SEQ_NR VARCHAR(255) '@SEQ_NR’,
SEQ_ANS_NR VARCHAR(10) ’../@SEQ_ANS_NR’) MS
INNER JOIN USL_WYK_TEL_INFO UI(NOLOCK) ON TI_NUMER_ELNET = NR AND SEQ_NR = TOIPMAIL_ID
WHERE SEQ_ANS_NR>= ISNULL(TOIPMAILRET_ID,-1)
EXEC MASTER..SP_XML_REMOVEDOCUMENT @IMSG
END
—
END
mała errata : 20040 –> 2004.